
Shiny-Based ANOVA Tooling
This repository documents the development of a set of Shiny-based ANOVA analysis tools, along with report templates and exploratory scripts used to refine both the statistical workflow and the user experience. The primary focus is on building interactive, reproducible one-way and two-way ANOVA applications that support data cleaning, model fitting, diagnostics, post-hoc testing, and automated reporting. The repo intentionally contains multiple generations of prototypes, intermediate versions, and finalized apps, reflecting an iterative design process rather than a single monolithic solution.
Core Purpose and Scope
At its core, this project aims to lower the friction between raw experimental data and statistically sound ANOVA results. It combines:
- Interactive Shiny apps for one-way and two-way ANOVA
- RMarkdown report templates for standardized outputs
- Standalone analysis scripts used to prototype features and validate assumptions
Rather than hiding statistical steps behind a black box, the apps explicitly surface model structure, diagnostics, and assumptions, making them suitable for both applied analysis and teaching.
Primary Shiny Entry Points
Several Shiny applications coexist in the repo, representing increasing levels of maturity.
One-way ANOVA apps
app.R: A basic one-way ANOVA app with four tabs covering data upload and variable selection, ANOVA summary, post-hoc testing, and assumption diagnostics. It relies onaov,TukeyHSD,multcompView::multcompLetters4,ggplot2,plotly, andDT.app_v2.R: Extends the same statistical core by introducing a user-driven data cleaning workflow usingrhandsontable, allowing edits prior to variable selection and analysis.oneway_app.R: A more mature implementation that formalizes multi-step data cleaning, integratesemmeansandeffectsize, adds improved color handling (viridis), and supports report generation viarmarkdown.
Two-way / RCBD-style app
- A separate
app.R(two-way variant) mirrors the one-way UI flow but supports two-factor models, incorporatingemmeans,tibble, andRColorBrewerfor interaction effects and visualization.
Report Templates and Reproducibility
The repository includes multiple versions of ANOVA report templates:
full_report*.Rmdfull_report_template*.Rmd
These files track the evolution of report structure and content, with full_report_template.Rmd and full_report.Rmd representing the most stable formats. In the finalized one-way app, these templates are intended to be rendered programmatically from Shiny, enabling consistent, reproducible reporting directly from interactive analyses.
Analysis Scripts and Iterative Development
A large portion of the repo consists of exploratory and transitional scripts, including:
final_V*.Rtwoway_V*.Rskeleton*.Rmini*.Rapp_old*.Rapp_withposthoc.R
These scripts reflect incremental feature development—data cleaning logic, alternative post-hoc strategies, plotting experiments, and UI layout trials. Rather than being deprecated silently, they remain in the repo as a record of design decisions and statistical validation.
Generated Assets and Outputs
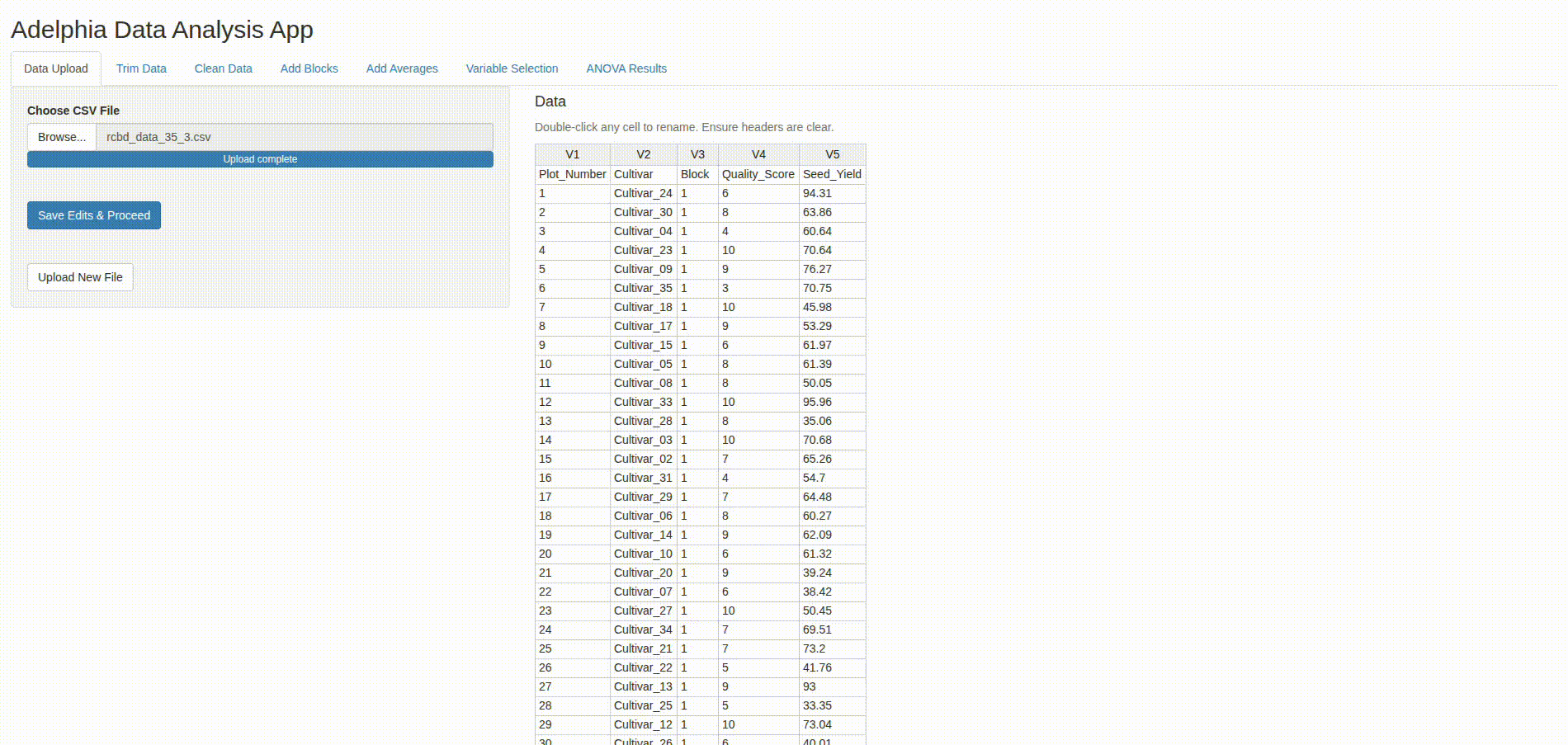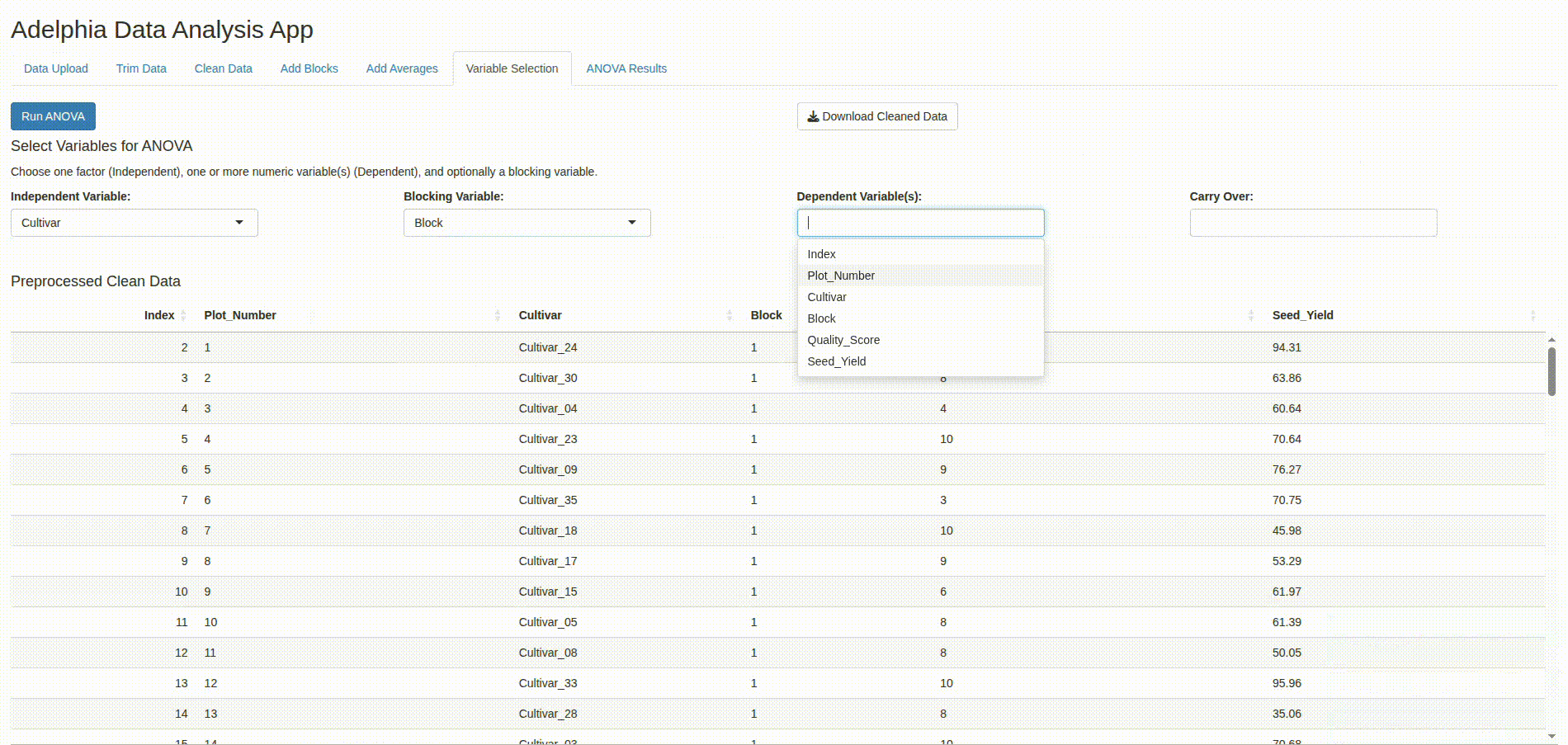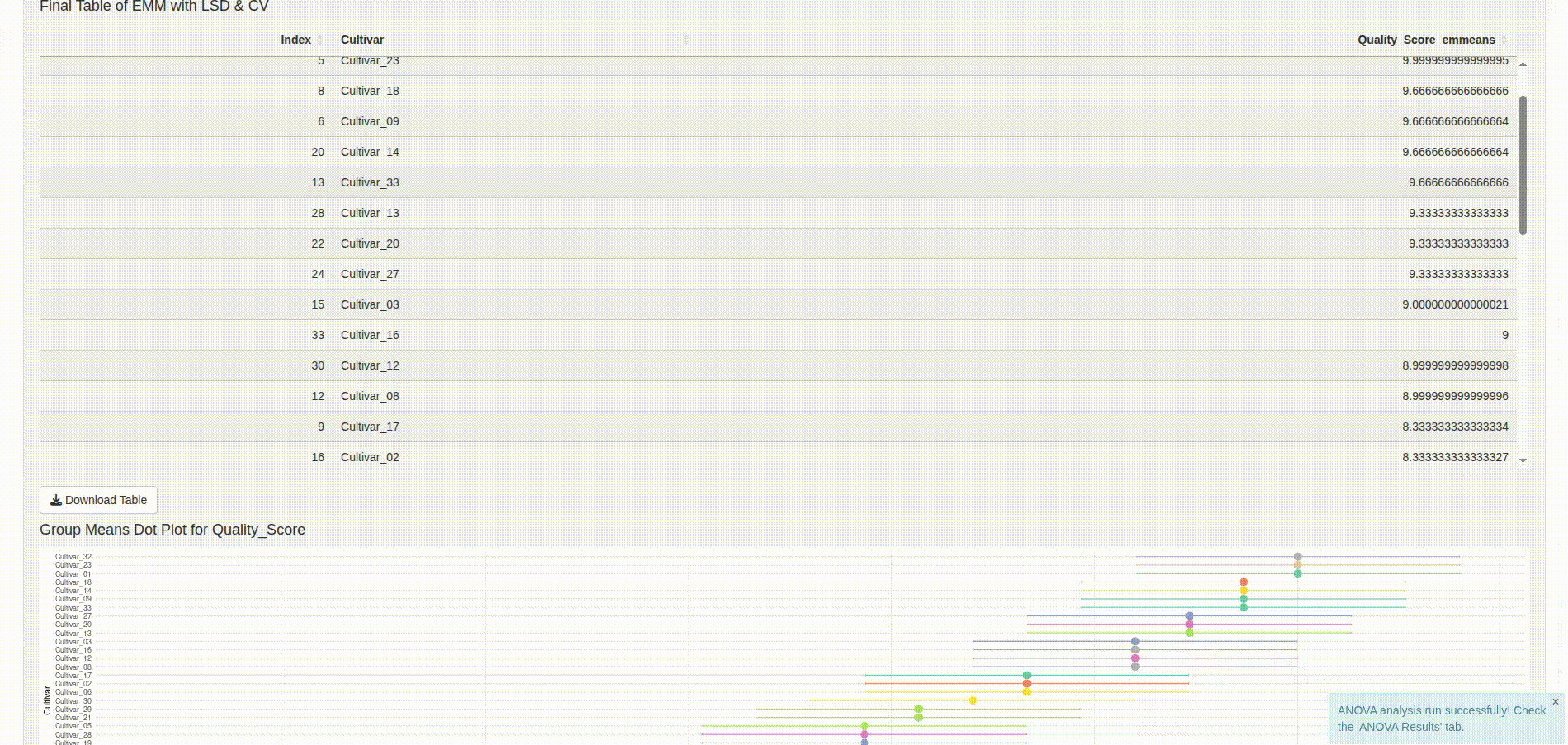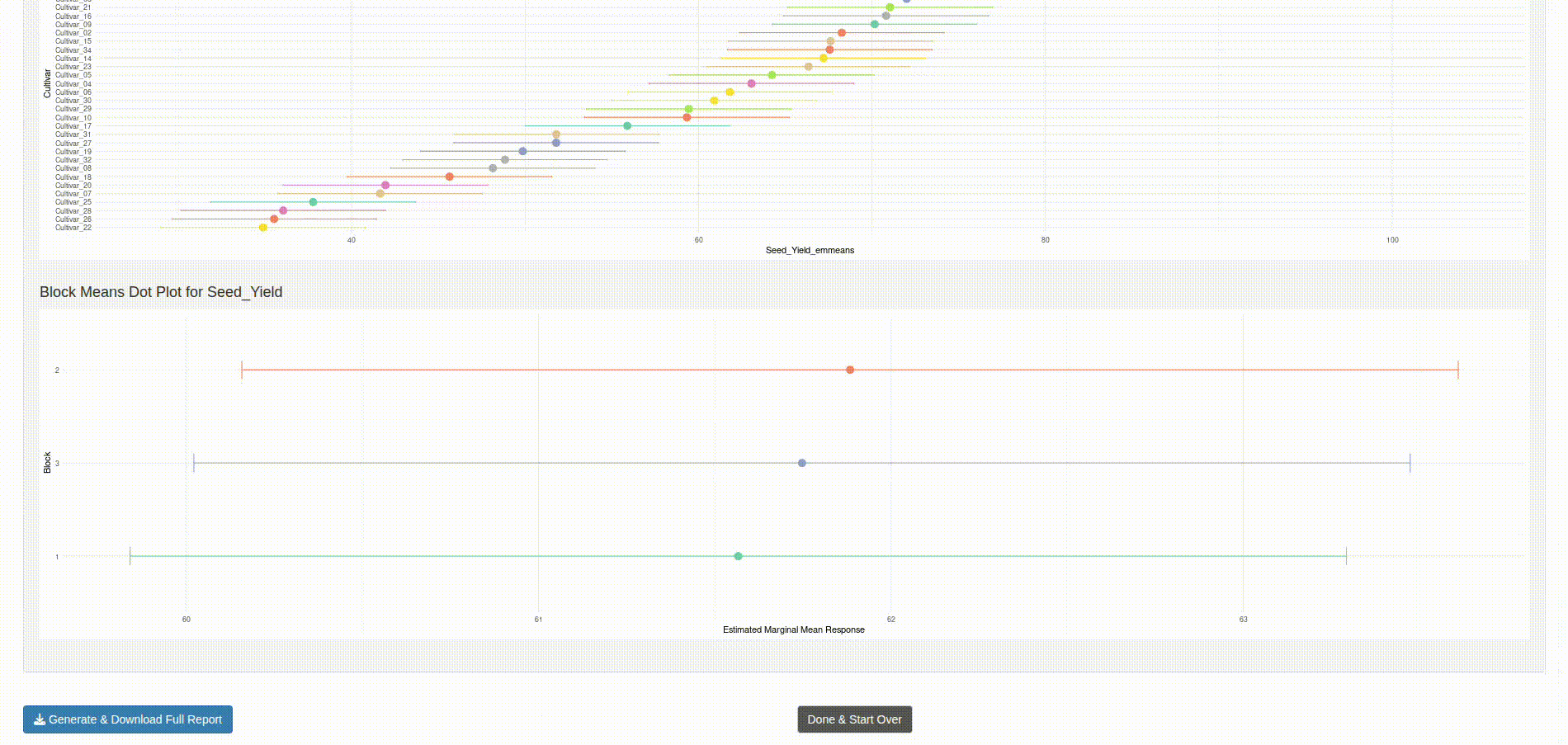
Numerous PNG files (e.g., group means plots, post-hoc visualizations, QQ plots of residuals) are present as artifacts of report generation and script execution. These serve both as visual references and as sanity checks for statistical behavior noted during development.
Key Dependencies
The project relies on a standard but carefully chosen R stack:
- Shiny/UI:
shiny,shinyjs,rhandsontable,DT - Statistics:
stats::aov,TukeyHSD,emmeans,multcompView,effectsize - Visualization:
ggplot2,plotly,viridis,RColorBrewer - Data handling:
dplyr,tibble - Reporting:
rmarkdown
Workflow Pattern
Across apps and scripts, the technical flow is consistent:
- CSV ingestion via
fileInput - Optional user-guided data cleaning (row/column trimming, editable tables)
- Variable selection (numeric response, categorical factor(s))
-
Model fitting using
aov- One-way:
response ~ factor - Two-way / RCBD: additive or interaction models
- One-way:
- Post-hoc testing (Tukey HSD, compact letter displays)
- Diagnostics (boxplots, residuals vs fitted, QQ plots)
- Optional report rendering via RMarkdown
Project Structure Signals
The directory structure reflects active experimentation:
ONE_WAY_ANOVA_FINAL/andTWO_WAY_ANOVA_FINAL/appear to be the most stable deliverables- Root-level files include exploratory versions, backups, and transitional drafts
- The README emphasizes the one-way workflow while noting extensions to two-way and RCBD designs
This layout is intentional: it prioritizes transparency in development over aggressive pruning of intermediate work.